
Evaluating a RAG application
Building a RAG is not enough, let's learn how to evaluate it.

A Retrieval Augmented Generation (RAG) system without evaluation is like a ship without a compass, drifting aimlessly on vast oceans without direction.
Today, we learn how to evaluate a RAG pipeline using a set of question-answer pairs (ground truth) as an evaluation dataset.
Here's what we'll do:
Build a RAG pipeline using LlamaIndex
Evaluate it using RAGAs
Implement observability using Arize Phoenix
So before we dive in, check out this demo:
Key RAG eval metrics
To evaluate a RAG, you'll need:
Ground truth QA pairs (eval data)
A critic LLM (LLM judge)
An embedding model
We'll assess our RAG pipeline using four key metrics, briefly explained below:

Code walkthrough
Let’s see things in action and understand the code for it, i’ve shared link to the code at the end.
Load test dataset
We'll only need questions & ground_truth answers, check this out:

Setup a RAG pipeline
A typical LlamaIndex RAG pipeline that we want to evaluate:

Set up things for evaluation
You can think of your RAG `query_engine` as a model that we want to evaluate.
Now, we run the query_engine on the eval dataset & collect response (just like doing inference):

Evaluate
Now that we have Questions, ground truth answers as well as generated answers, we're all set to evaluate our RAG pipeline.
Here's all the code you need for it:
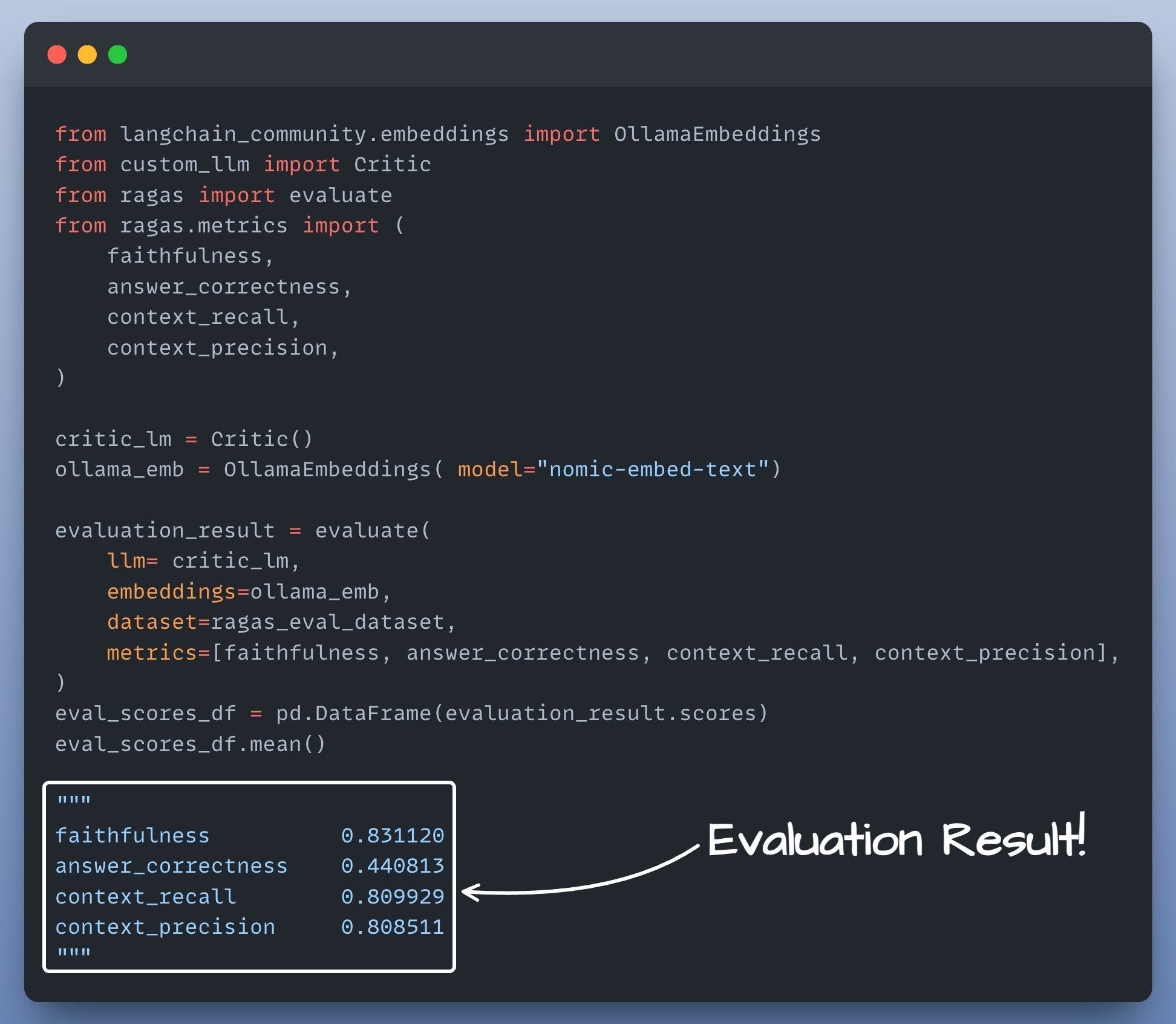
Find all the code here
I've published this work as a LightningAI⚡️ Studio!
You can find all the code & environment to reproduce it in just a click of a button.
You'll also find the code for visualisation using Arize Phoenix!
Check this out:
https://lightning.ai/lightning-ai/studios/evaluate-your-rag-application?utm_source=akshay
That’s all for today, I’ll see you in another post on AI Engineering next week.
Make sure you subscribe to not miss out and support my work here.
Cheers! :)